The good folks at Adobe just posted a huge article by Tamye Riggs covering Adobe’s type history from about 1991–2006 or so, focused especially on the invention and later abandoning of multiple masters and the rise of OpenType. It features the first and only public comment from Carol Twombly on her departure from Adobe and type design. It also has several quotes from me. 🙂
In general this is a really comprehensive article. Still, I am thinking I will write some more about the reasons OpenType succeeded where GX and MM did not.
(Note: Tamye’s series of articles on Adobe Type has been released as a full book. Very nice. Copies were in the conference-goers’ goody bags at TypeCon 2015 in Denver.)
I am not a huge Roboto-hater like some folks in the type community. I just object to uncritically publishing quotes that make blatantly false statements.
“UIs [user interfaces] are crafted from images and type,” Matias Duarte, Android’s head of design tells WIRED. “But the idea of having a typeface that’s thought out as a UI typeface—that’s not been done before.”
Well, that’s pretty much simply false. (UPDATE: Duarte says he thinks he was misquoted, basically he was trying to just say UI typefaces are hard, and Roboto had a particular challenge in needing to work in a wide range of contexts and types of devices.)
[Perhaps not Duarte, but apparently the Wired author was] unfamiliar both with an obscure operating system called “Windows” and its typefaces Segoe UI (introduced in Windows 7) and Tahoma (introduced in Windows 95), both of which were specifically designed/intended for UI usage. Not to mention Chicago, developed for the original Mac OS back in 1984. (UPDATE: Plus, there is Prelude, designed by David Berlow and Font Bureau as a UI typeface for the Palm Pre operating system—when Duarte himself was in charge of UI for the Pre. Not to mention Android’s own Droid Sans, also designed as a UI typeface.)
A slightly weaker argument could be made for Lucida Grande (the Mac OS X UI font), which is only slightly tweaked from Lucida Sans. Of course, Lucida Sans itself was specifically designed for low-res screens and the like. Designer Chuck Bigelow got a MacArthur “Genius” award for his work on the family.
There are seven substantial paragraphs to the article, but both the people quoted are on the Android team. Thus it avoids mentioning the most famous thing anybody has said about Roboto, ever: Stephen “Stewf” Coles calling it a “four-headed Frankenfont” in a strong attack on the design philosophy behind it.
This is also why there is so much puffery throughout the article emphasizing how the typeface is designed for performance rather than aesthetics. Such choices do certainly explain most of the changes from v1 to v2 of Roboto, but “performance over aesthetics” is clearly false as a general proposition about the typeface. My big problem with Roboto is that the choice of closed counterforms for many letters and numbers (35CGSacs) is an inherently anti-legibility choice. Yes, they had more of these before the revision, and some (5) have been slightly improved, but they need to finish the process of transforming it into a different typeface if they want it to be an outstanding UI typeface.
Indeed, I would argue that such closed shapes are stupid bordering on criminal in a user interface typeface. There is a reason that most other typefaces specifically designed for user interfaces have used open counters, and that is because there is massive evidence that tells us these shapes are more legible (see for example the research cited in Sofie Beier’s book on the subject). Legibility should be a the paramount concern for a user interface typeface.
Roboto designer Christian Robertson explains the mix of open and closed shapes as saying that they create an appealing texture in body text. Which is lovely and all, but in a user inferface, that is not as important as legibility.
That said, to be fair, Apple is doing a much worse thing in choosing Helvetica Neue as their UI typeface, first for iOS and soon for the next version of OS X. They too have gone to lengths to declare publicly how they are optimizing it for legibility, which is rather like trying to polish a turd. Helvetica is inherently anti-legibility. The only way to make it otherwise would be to change it so much that it doesn’t look like Helvetica any more. Sadly, that is not what Apple is doing. (Update: Apple later changed to San Francisco, which has the same “modern” look as Helvetica, but with just slightly more open counters… rather like Roboto in that regard.)
Aside from the business of being first with a dedicated custom UI font, if Google and Apple were to explain that they are making their UI font choices for design reasons, that’s fine. But when they (or Wired) start touting the awesome legibility and functionality of their choices, I have to call them out on it. Nonsense.
Are you a user of fonts who needs to tell if a font is well made, or an aspiring novice type designer? The March–April 2014 issue of Communication Arts features my article on evaluating font quality, “How to Tell If a Font Sucks,” on p. 24—now online as well!
It looks like it is hard to see the subtleties in some of the graphics in the down-res web-ified version of the article, though the print mag looks great. I will see about posting a version with high-res images in PDF.
I’m really pleased with this article. My new editor Robin Doyle at CA did a great job helping me clarify some points and figure out where more graphics were needed.
That said, there are some corner cases and subtleties around this discussion that I didn’t have time or space to get into in the article, which was already long and involved. But that is what blogs are for. 🙂
Although I stand by everything in that article, typefaces that are deliberately naïve/unsophisticated are one place for legitimate exceptions to some of the guidance I give in the article. For example, I had a lovely discussion with some folks who made a typeface based on some classic road signs. The original signs did not use optical compensation at stroke joins (point 5 in the article), so they didn’t do it in the typeface either. Although I might rarely be interested in going that way myself, I have to agree that it was a perfectly legitimate design choice, given the origins of the typeface as a signage revival—even though in many another context I would be calling it crap!
Optical compensation at stroke joins is also specific to certain typographic traditions. Certainly for Latin-based fonts (English, French, German, Hungarian, etc.) it is nearly universal, as it is for Cyrillic (Russian, etc.) and Greek. But some writing systems do things differently, such as Devanagari (used for Hindi, Marathi, Sanskit).
Non-western writing systems can also change other assumptions. For example, the idea that straight-to-round transitions (point 6 in my article) should be very smooth is very much not the case for Thai.
Anyhow, check it out and let me know if I can clarify anything else!
Last week I wrote about posting five FontLab encoding files for Adobe Latin character sets.
Today I posted in the same Github repository three FontLab encoding files for Adobe Cyrillic character sets, and updated the five Latin files with a few added currency symbols and glyph name changes (as I expected I might).
The character set definitions underlying these files were built on a bunch of research I did at Adobe back in 2006–08, with additional work by Miguel Sousa. The headers include much detail on the differences between each set, and the languages covered. Both of these character sets reflect the latest data from Adobe on how they name glyphs and what they are including in current fonts (not including OpenType alternates and features, mind you). The headers of the files have some interesting details and history, especially on the Cyrillic side.
Thanks as always to my old friends at Adobe, including Miguel and David Lemon, for their willingness to share production information with the type design community.
I dedicate this post and my work on the Cyrillic encoding files to the memory of Emil Yakupov, CEO of the ParaType type foundry in Moscow, who passed away just a month ago at the age of 56. His advice and feedback on Cyrillic character sets—among many things—was invaluable to me. I remember one of our first meetings, when Emil gave me a pair of ParaType catalogs as I was first becoming involved with Cyrillic type design. I still consult them to this day when trying to internalize what forms different Cyrillic characters can take in different font styles.
To install, quit FontLab, find the “Encoding” folder in the shared “FontLab” folder, and drop the files in there. Restart FontLab and these will be available as encodings.
NOTE: These were later updated to reflect minor tweaks Adobe has made since I described the character sets and posted the data, almost six years ago. I added currency symbols such as the Indian rupee, Turkish lira, Russian ruble and Ukrainian hryvni, and changed a few glyph names to match current Adobe practice. Thanks as always to my old friends at Adobe, including Miguel and David Lemon, for their willingness to share production information with the type design community.
This follows a couple of possibly-useful FontLab scripts I posted a couple of weeks ago, in the same place.
I have started posting a few scripts in my own repository on GitHub. They are libre (free, open source) under an Apache 2.0 license.
Generate-substitutions.py: Select some glyphs in the font window. Run the script. It will automatically generate useful OpenType feature code (in .fea/AFDKO syntax) in the Output window, which you can copy/paste right into the appropriate feature. The script works with both simple substitutions and ligatures as long as you follow standard Adobe glyph naming standards (appropriate use of period and underscore). It does not work with complex cases involving multiple-feature interaction, sorry.
Make-numbers-from-dnom.py: First you need to create some numbers sized and positioned for use as denominators. The script will take all the glyphs in your font ending in “.dnom” and create numerator, superscript and subscript versions using the dnom glyphs as components. If the font is an italic font, it will use the italic angle of the font to calculate how much to shift the components horizontally while moving them vertically. NOTE: the vertical shifts are hardcoded in the script now, but easily edited. Future improvement ideas: pop up a dialog to enter the vertical shift numbers, and/or try to auto-calculate them.
Unfortunately, my “best” (or at least most complicated) script is very specific to my workflow on developing my Cristoforo family (it does the steps detailed at the bottom of this blog post). It is a heavily modified version of Ben Kiel’s “Better Generate Font” script. I chose not to post it as the workflow is just so very peculiar to my needs and does things like put my license URLs in the font, but if you want it for some reason, perhaps as a starting point, ping me.
I am very excited to be getting my visa for India today! I’m one of the instructors for a 3-day advanced type design workshop with FontLab. Registration is now open on the FontLab blog, and there is a detailed schedule of planned talks.
One problem with releasing lots of pre-release builds to my Kickstarter backers is that I don’t test every single one as much as I otherwise would. Generally any errors are minor, but earlier today I managed a moderately important one: I didn’t remove overlapping paths in my outlines during the build process. Well, actually, I did remove overlap, but as I did not first decompose my composite glyphs, it didn’t fix most of the problem cases.
Why would you want to have overlapping paths in your glyph outlines, and why/when would it be a problem?
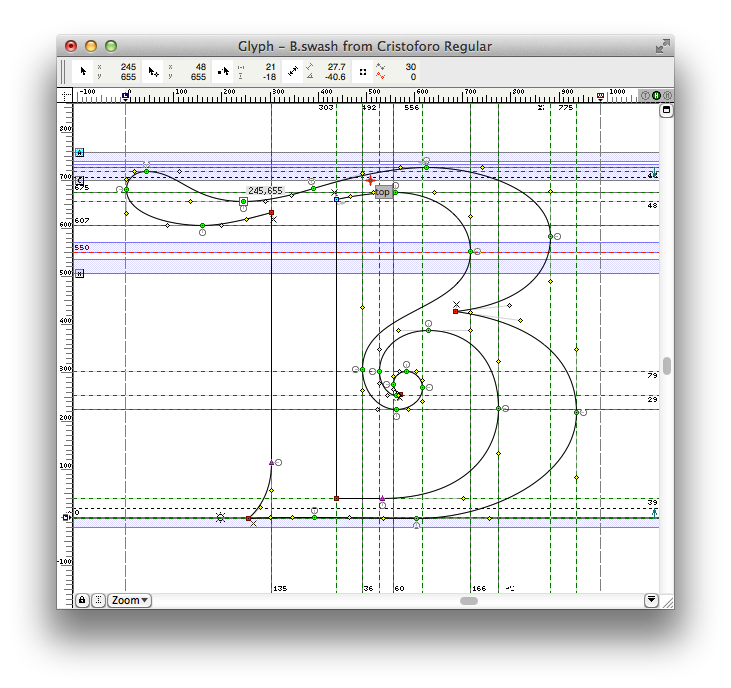
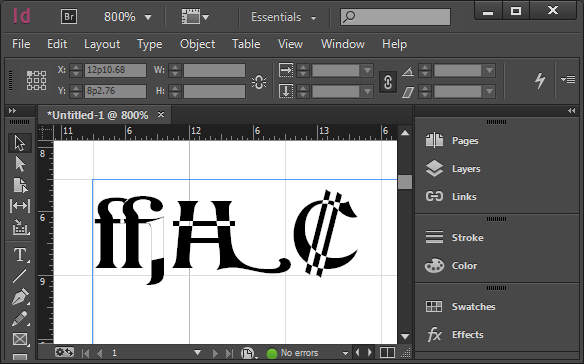
Here are several glyphs (as shown by H. James Lucas) that had overlapping paths in this last build:
Overlapping paths rendering badly in Adobe InDesign
So, clearly it’s a problem if they render badly in some apps. Interestingly, this is dependent on not only what is doing the font rendering, but also what size the glyphs are rendered at. Adobe’s core rendering engine has three or four different rendering modes, and what it picks is size-dependent.
Overlapping paths are sort of okay in TrueType fonts—the rendering engines will deal with them better. But they will still produce bad results if a user does something like apply an outline or stroke to the text.
So why do I leave these things in while developing the font? Well, during development, it is useful to keep the basic elements separate, and only remove overlap later on. So for example, if I change the underlying swash H glyph, I want the Swash-H-with-bar to automatically pick that up. Similarly, the C shape seen in the colon currency symbol (used in Costa Rica and El Salvador) is shared between the Ghanaian cedi, the euro symbol, and a stylistic variant of the cap C. I used the same primitive elements in the ffj ligature in numerous other ligatures (including ffi). And so on.
Of course, as leaving overlaps in the final font causes problems, normally I take care of this as part of each build. My usual build sequence for creating OpenType OTF fonts from my FontLab file:
Create a “next version” and make sure version string has been correctly incremented (in several places), including in the file name itself.
With the current version of the file
Remove all hinting (shift-F7 in FontLab Studio 5 for Mac)
Select all glyphs in font (Cmd-A in FLS)
Autohint all glyphs (F7 in FLS)
Save file
Then the following actions, done without saving the file again, to preserve original data in the FontLab file:
Decompose all composite glyphs
Remove overlap (Cmd-F10 in FLS)
Export OTF font (Cmd-Opt-G in FLS) with correct version number in the file name
Change license URL string to point at the personal license
Export OTF font again with “-NC” (non-commercial) in the file name, in addition to the version number
Close font without saving file
Anyhow, in this particular build I missed the “decompose” step, so all overlaps involving composite glyphs (most of them) still overlapping. Of course I have fixed this, and am sending revised fonts to my backers.
Adding kerning is one of the very most tedious tasks in developing a font, if it is done well. It is also the final major production task in type design.
As I am finishing this stage on the Regular style of my Kickstarter typefaceCristoforo, and about to send updated fonts to my backers, I find myself needing to explain what this kerning business is, anyway. So I thought I would post something here for general public consumption, and point to it from my latest Kickstarter update.
In fonts, each glyph is placed in a slot with a certain amount of space allocated to it, which generally includes white space on either side. The total horizontal space allocated to a glyph is its “advance width.” The distances between the furthest extent of each side of the glyph and the ends of the allocated space are the “sidebearings”—which can even be negative numbers, if part of a glyph sticks into a neighboring space.
In high-end type design, spacing is an especially complex art and craft. But many junk fonts don’t even get the basics right, and that is easily detected. Decent spacing is consistent, and follows certain general principles about shapes. Consistency means the “same” elements should get the same space across different glyphs, and similar elements spaced similarly. So the left sidebearings of OCGQ and the right sidebearing of D are all usually either the same or very close.
Designing even spacing is about keeping a relatively consistent amount of white space between letters. In a typical sans serif font, a letter like O only needs 50–60% as much in the way of sidebearings as an H. Something like a T or a V might have sidebearings at or close to zero. Lowercase letters are generally spaced slightly closer than their cap brethren.
Inconsistent treatment of sidebearings makes this geometric sans serif typeface less useful. (click for full-res image)Consistent and reasonable (if uninspired) spacing in a sans serif font. (Click for full-res image.)
The word “kerning” can refer to any of three things:
noun: data in a font that adjusts spacing for particular letter combinations.
verb: the act of creating such data
verb: when setting text, the act of adjusting space between particular letters in text. This is an operation done by a typesetter in text setting software, and is not a font editing operation. Also, not to be confused with tracking, which is adjusting the overall spacing of a block or range of text all at once.
For purposes of this article, I’m concerned with the first two definitions: kerning data built into fonts, and how to create that data. We’ll get to the “how” later, first let’s talk about the “what.”
It’s critical that the basic spacing be done well in any font, but for particularly difficult combinations, the font should also contain built-in kerning (which can help avoid the need for the end user to do manual kerning). Kerning is a set of adjustments to the default spacing for specific troublesome letter combinations, so as to deal with fact that, without intervention, “AV” will be set too far apart, or that in some fonts “f)” will make the top terminal of the f collide with the parenthesis. Vast amounts of kerning are not always a necessity for a well-made font, but if there is no kerning, or if it does not deal with common situations like “LT” and “To”. . . then there is something wrong.
Making Kerning
In the “old days” prior to about 10–15 years ago, kerning was done by defining pairs and adjusting the spacing. So combinations such as To and Te would be separate pairs, as would VA and WA. This was a pain, but still manageable as long as fonts still only have <256 glyphs per font, although some would end up with thousands of kerning pairs, and some apps would break (in different and interesting ways) when working with very large amounts of kerning data.
But it is not unusual for an OpenType font to have a thousand glyphs or more. Cristoforo Regular has 1324 glyphs now. Luckily, OpenType allows for “class kerning,” in which glyphs can be grouped into classes, and then the classes are kerned instead of individual glyphs.
So the first thing to do is to define those kerning classes! I spent days on and off just doing that for Cristoforo Regular. Some of them only apply when the class is on the left, some when the class is on the right, and a few apply to either side. I had 96 kerning classes before I started kerning. I made a few additions and deletions during the process, and am sitting with 101 right now, with 632 distinct adjustments between classes (the class equivalent of “kern pairs”). Probably a week or more of work, if it was full time.
Here’s the display of classes in FontLab Studio 5.1.4. Most of my classes for Cristoforo have anywhere from 4–30 glyphs, but some have just one or two, and the largest has 84.
The left listing has all the classes, along with whether they are left side, right side, or both. The selected class is a left side class, composed of capital letters with round left sides, such as CGOQ. (Click for full size image.)
Getting the class definitions right is critical. If a glyph is missed out, it doesn’t get kerned. If a glyph appears in two left-side or two right-side classes, it causes an error that means that a bunch of the kerning will never be applied when the font is used. (FontLab Studio warns appropriately, but debugging can take a while.)
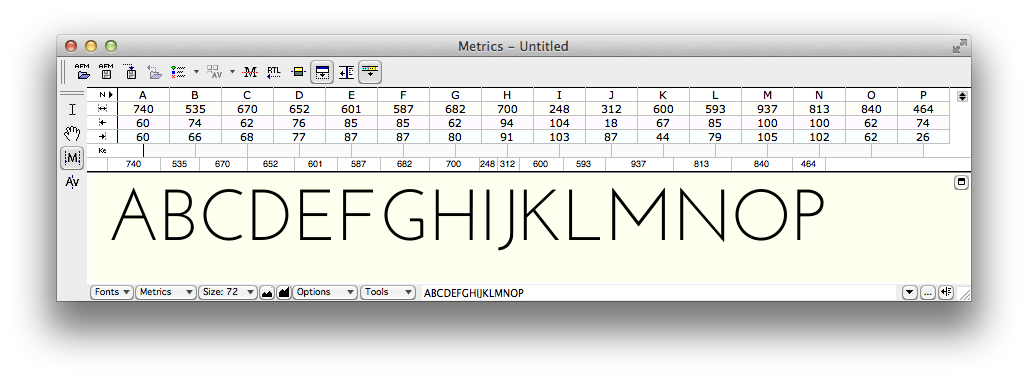
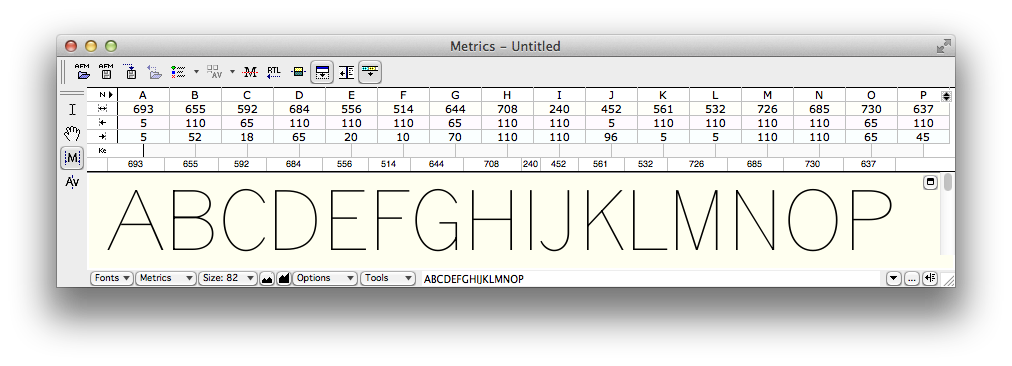
Here is how the spacing can be viewed with arbitrary strings of text in the metrics window. At the moment the effect of kerning is not being shown.
FontLab Studio metrics window showing advance widths and sidebearings for unkerned text. (Click for full size image.)
Below you can see the same text only with kerning applied.
Effects of kerning are shown. The metrics listing above the text only shows those pairs for which both members are considered the primary exemplar; other combinations are often kerned as a result of class membership. (Click for full size image.)
The next version, below, highlights the points where kerning is happening. Mostly kerning makes the combinations closer together, except the “e.” combination, where the period has to be moved a smidge further away.
FontLab Studio metrics window showing advance widths and sidebearings for unkerned text. (click for full size)
Application Support
Most graphics and publishing apps simply use the kerning data in the font by default. You have to do something special to avoid it or get different results. This is true of Photoshop, InDesign, Illustrator, and QuarkXPress.
The Adobe apps refer to the kerning built into the font as “Metrics” kerning, as opposed to no kerning or Adobe’s automatic “Optical” kerning. In a well-made font Metrics kerning produces the best results, but even then Optical kerning can be handy for combinations the type designer missed, or situations that can’t be handled by kerning built into the font (such as kerning between different font sizes or two entirely distinct fonts).
Even WordPerfect, back around 1990, had kerning on by default, if I remember correctly. But not Microsoft Office.
Microsoft Word has allowed you to turn on kerning pretty much forever, it just defaults to being off. To turn it on, in recent versions, go to Format > Font or hit Ctrl-D (Cmd-D on Mac). You’ll get a big dialog. Select the “Advanced” tab.
Then in the top “Character Spacing” section, check the box that says “Kerning for Fonts.” The default is to set kerning on for 12 point and above, but you can reduce it—I generally set it to 1 point because I want kerning on all the time. Unless I am writing an article about kerning I never want it off.
Kerning dialog in Microsoft Word 2011 for Mac (Word 2010 for Windows is similar)
PowerPoint has more recently started supporting kerning. In more recent versions, go to Format > Font or hit Ctrl-T (Cmd-T on Mac). In the resulting dialog select the “Character Spacing” tab. Then check the “Kerning for fonts” option.
Kerning dialog in Microsoft PowerPoint 2011 for Mac (PowerPoint 2010 for Windows is similar)
So that’s all you need to know to use and appreciate kerning!
NOTE: About 1/4 of the text of this post is borrowed from my article “Know If a font Sucks,” currently in press for the March–April issue of Communication Arts.





")
")